The one thing that bugs me about creationism is they rarely put forth any real research (and what they do make is usually revealed to be crap based on shoddy data). They love to point out anomalies such as soft tissue remnants in fossils and claim that it’s flat out impossible for it to be there if the fossils are ancient. There’s no good reason to think this, as the processes which form the rock are far better established than long term tissue decay rates in dinosaur fossils.
But what I consistently notice is they’ll use things like soft tissue to try and advocate their position must be right by default. I mean, how else would you explain these discoveries???
I don’t know. Scientists are only just beginning to find out what mechanisms may play a role in preserving tissue remnants over long periods of time. But what needs to be made absolutely clear, and that creationists just can’t seem to get, is that even if we don’t know how these anomalies came to be, that does not prove their global flood at all. The simple fact is their global flood idea has been falsified over and over, and over, and over again. A falsified model, which I will show as conclusively falsified below, is not the answer.
Now then, how do we know, conclusively, that a global flood as advocated by YECs never happened? It’s all due to this lovely branch of geology known as Chemostratigraphy.
Chemostratigraphy is the study of the chemical variations within sedimentary sequences to determine stratigraphic relationships.(1.) This obscure subdiscipline in geology completely undermined every young-Earth interpretation of the geologic column. Before reading any further, I’d highly advise reading the crash course on chemostratigraphy at AgeofRocks.
To sum it up, Chemostratigraphers can use the ratios of certain stable isotopes, such as Carbon 12 or 13, to determine the chemical make ups of rocks and graph them stratigraphically. Often this is because the isotope ratios will record certain events from the time periods when the rocks were laid down, such as the carbon levels in the ocean.
Here’s the analogy from AgeofRocks:
Perhaps the best way to illustrate isotopes of carbon in the ocean is with a bowl of red and green M&M’s, where each color corresponds to a different stable isotope of carbon. For the sake of discussion, this bowl contains precisely 50% green M&M’s (light carbon) and 50% red M&M’s (heavy carbon), for a ratio of 1:1. Now, imagine you leave the room and return later to find that the ratio has shifted to 0.9:1.1, meaning the bowl has been enriched in red M&M’s. There are two possibilities that could explain the shift: either someone added a sample containing more than 50% red M&M’s, or someone removed a sample containing less than 50% red M&M’s. Perhaps you have a child, therefore, who prefers one color to the other, so every handful he takes is biased to that color. This process will leave the bowl preferentially enriched in the other color. If every handful contained precisely half green and half red M&M’s, then the ratio of green to red in the bowl would never change. Likewise, any process that removes carbon from the ocean will change the δ13C value of oceanic carbon, so long as the isotopic ratio of the sample differs from that in the bulk ocean.
Typically, we can use index fossils and radiometric dating alongside stratigraphy to determine that, for example, a rock layer in Nevada is the same age as a rock layer in southern China (perhaps they both contain a unique assemblage of Cambrian-aged trilobites). According to a flood geologist, these layers were deposited in a single year around 5000 years ago. However, they were not necessarily deposited [i]simultaneously[/i]. So, if the fossils are in the same order, it has to be due to hydrological sorting or ecological zonation. Regardless of how the order arose, one thing is certain: if these marine organisms were all buried in a global flood, then all of them made their shells from the [i]same ocean and the same reservoir of carbon with approximately the same isotopic ratio.[/i] So when fossilized shells of trilobites, brachiopods, mollusks, etc. are analyzed across the Phanerozoic (542 Ma – Present) for carbon isotopes, flood geology would predict that the levels of carbon found in all of these animals, regardless of where in the column, should have an equal amount of the same isotopes.
But this is not what we see. (3.) Instead, what we see are patterns of fluctuating isotopes. This is best illustrated by the graph from Veizer et al.,
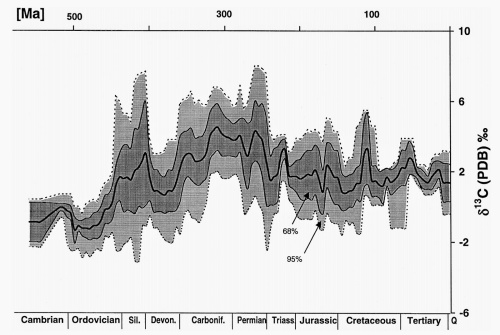
The graph shows that the carbon-isotope ratio in carbonate fossils—and therefore the ocean itself—varied substantially over the past 500 million years. This is in direct conflict with what one would expect had these fossils all been laid down by a single flood. Because the carbon reservoir in the ocean is so large (today, about 39,000 billion tons of carbon), the color of this bowl of M&M’s does not change appreciably on a whim—certainly not in the space of a 370 days. It takes time. Thus, chemostratigraphy leaves the creationist idea of a global flood dead in the water.
To be through, I’ll use the possible immediate objections to chemostratigraphy here, with refutations:
The flood caused wild variation in carbon isotopes!
Variations in the carbon-isotope ratios of fossils are far too great to be explained by shifting ocean chemistry within a single year, meaning these organisms could not have lived in the same ocean at the same time. See the attached graphic above. There would also need to be a mechanism for the addition and removal of massive amounts of carbon isotopes (2.), making the idea even less likely.
What’s more, the pattern of carbon-isotope variations from Cambrian to Quaternary is the same across the entire globe. Whether you’re sampling rocks from Texas or Tanzania, layers of limestone determined to be the same age according to their fossil content also exhibit the same pattern of δ13C values over time. These values are invariably high for Permian-aged carbonates and invariably low for Ordovician-aged carbonates.Consider the fact that in order to increase the oceanic δ13C value by only 5‰ requires a sustained doubling in the rate of organic carbon burial for about 1 million years. There is no reason for any proposed fluctuations in the flood to have been spread out evenly across these deposits all over the globe, especially not if all the sediment (and any carbon by extension) was getting mixed up prior to deposition. The values should be highly variable, not identical across the globe.
The animals in these areas prior to the flood lived in unique basins with different carbon ratios. Therefore, seeing their values varied like this should be expected.
If variations between one part of the ocean and another could account for trends in carbon isotopes, then we shouldn’t find the same temporal trends in different parts of the world (e.g. China vs. North America vs. Australia). Also, we find carbon isotope values changing significantly within the lifetime of single species (e.g. of Cambrian trilobites (4.) ), so one couldn’t claim that all those trilobites just lived in a unique basin prior to the flood. In every environment, the relative change in carbon isotopes correlates well from one site to the next. Finally, we can examine both carbon and strontium isotope trends to ensure that carbon variations weren’t limited to a unique environment (strontium isotopes don’t vary from one basin to the next). (2.)
Chemostratigraphy provides the final falsification of a global flood depositing all of the geologic column. It instead provided a wonderful opportunity to examine the chemical environment of Earth’s past and is a testament to an ancient world.
References:
1.https://en.wikipedia.org/wiki/Chemostratigraphy
2.http://ageofrocks.org/2014/08/23/chemostratigraphy-silent-objector-to-flood-geology/
3.http://www.sciencedirect.com/science/article/pii/S0009254199000819